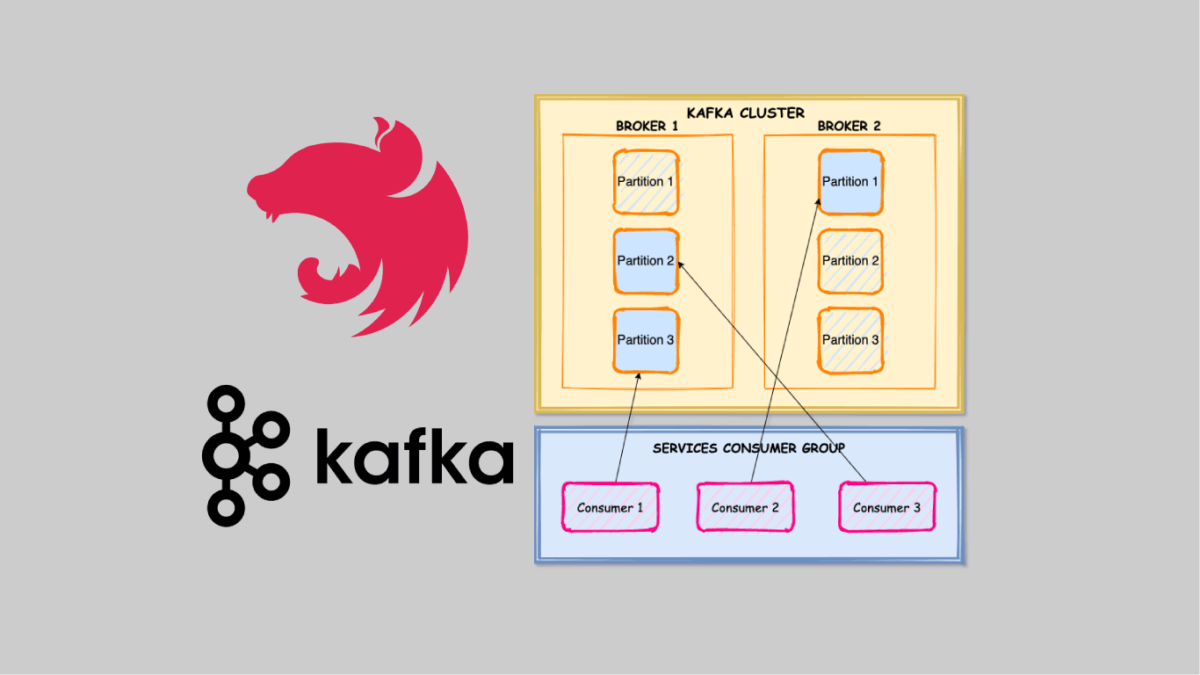
This is the second post in the “NodeJS Microservices with NestJS, Kafka, and Kubernetes” series, and we’ll build up the second application called microservices. The microservices application will connect to a Kafka cluster to consume the records pushed to a Kafka topic by the api application.
Before we begin, make sure you have a working environment by completing part 1 of this series.
The application structure we are going to explore is similar to what was covered in the first article, the only difference is that there is no exposed API.
NestJS and Kafka
NestJS provides a set of modules and utilities that make it simple to structure a new project. Additionally, NestJS provides built-in support for Kafka integration through the @nestjs/microservices and kafkajs library, which makes it easy to consume and process messages from a Kafka cluster.
The implementation we are going to explore is event-based and it is suitable for streaming of data or long-running tasks. Good examples of workloads would be ingestion of sensor data, streaming of logs, sending emails, generating pdfs, or processing big files. Kafka is a perfect solution for it because this kind of workload does not need to return a response.
The NestJS microservices suite also supports the request-response model. The Request-Response model is a perfect solution for microservices communication, where the caller microservice expects a response containing some data.
Although the @nestjs/microservices library supports both kinds of integrations, I do not recommend using it for the Request-Response model. When using the Request-Response model, NestJS returns the response through a secondary topic, that is by default, created by the application at runtime. This solution is not optimal and there are better tools suited for the job, like for example, gRPC. The gRPC integration is also supported by the NestJS framework and can be later explored in further articles.
Source Code
You may always check out my code for trying it out. In order to do so, clone the GitHub repository that we created in part 1 of this series and follow my directions from there.
Getting Started
It is time to create the microservices application. Make sure you are at the root of the repository before running the following commands to create the project and install the necessary dependencies:
After creating the project, we are going to create the services domain controller to handle the events sent by the API to the services topic.
Let’s modify the src/services/services.controller.ts. file to include the code necessary to process the messages from the services topic.
import { Controller, Logger, ValidationPipe } from '@nestjs/common';
import { EventPattern, Payload } from '@nestjs/microservices';
@Controller()
export class ServicesController {
constructor() {}
@EventPattern('services')
serviceEvent(@Payload(new ValidationPipe()) msg) {
Logger.debug(msg, 'ServicesController');
}
}At this point, the controller is ready to consume the messages sent to the services topic.
It is time to get all the pieces tied together. Before proceeding, it is necessary to follow the instructions described in the first article to start the Kafka cluster and the api application. After the setup is done, make sure to restart the microservices application as well.
To validate the setup, we are going to send a POST request to the /services endpoint to send a Kafka message to the services topic.
Validating DTOs with Class Transformers and Validators
A Data Transfer Object (DTO) is used for defining messages that are sent between the caller microservice and the callee microservice. It can also be used to define messages that are sent between different components of a single application.
When working with DTOs it is important to always validate their content before sending them down to another layer to be processed.
The microservices project is going to process three DTO events types for the services domain, which are ServiceCreated, ServiceUpdated, and ServiceDeleted. The event classes are going to inherit from the parent EventDto class to facilitate the parsing by utilizing its eventType property.
src/services/dto/event.dto.ts
src/services/dto/create-service.dto.ts
src/services/dto/update-service.dto.ts
src/services/dto/delete-service.dto.ts
src/services/dto/kafka-service.dto.ts
The KafkaServiceDto uses the class transformer @type decorator to differentiate the many possible received payloads, making sure to validate them using the class validators defined on each type.
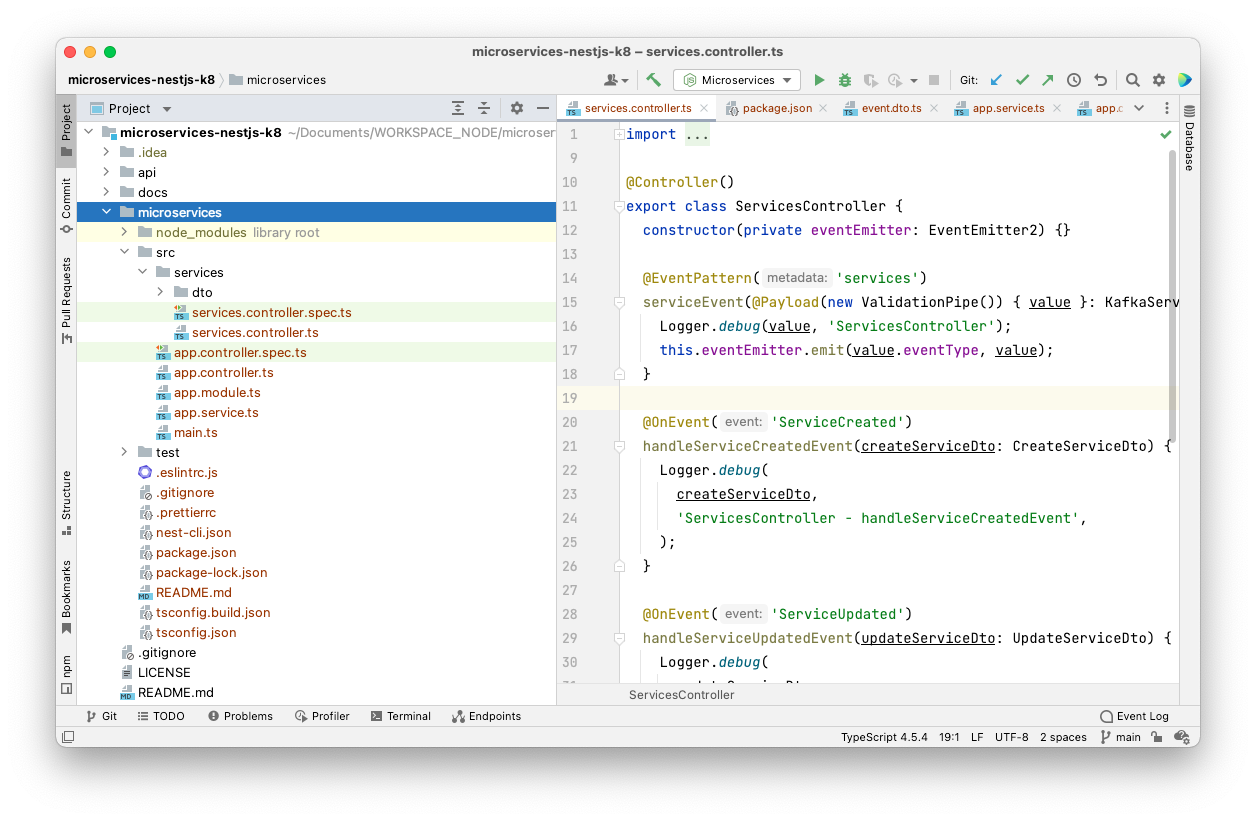
After defining the DTOs, it is necessary to adapt the service class to handle the different event types.
src/services/services.controller.ts
By looking at the updated service class source code, some of you might be wondering why is the @OnEvent annotation being used, instead of the @EventPattern. This is because we want to achieve ordering while processing the events.
That is all the code you need for consuming and validating messages from a Kafka topic using NestJS and its @nestjs/microservices library.
Achieving FIFO Using Kafka
When it comes to processing events, it’s sometimes important to ensure that they’re handled in the correct order. This is especially true when it comes to messages being sent to topics with multiple partitions. If messages aren’t handled in the correct order, it can lead to unpredictable results and data inconsistencies.
Let’s imagine we are sending two ServiceUpdated events with different prices per hour for web development, the price in the first message is 20, and in the second is 200. If the messages are not processed in order, it might happen that the latest price is set to 20 instead of 200, causing inconsistencies when a user is going to request a service quote.
To solve this problem we need to ensure that the records related to a specific entry are always sent to the same topic partition.
Kafka Partitions
Partitions are a way of dividing data into separate groups so that it can be processed more efficiently. It makes it possible to send and consume messages faster by allowing consumers to read from specific partitions or even multiple partitions at the same time.
When a producer send a message to a topic, it is assigned to a specific partition based on a set of criteria. The default strategy is to choose a partition based on the hash of the message key (when it is present). If a key is not set, Kafka pushes the message to the partitions in a round-robin fashion. Lastly, it is also possible to implement a custom partitioner to decide which partition is going to receive the message.
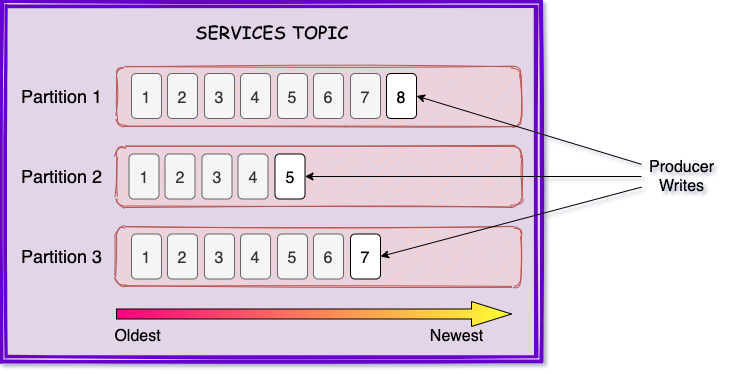
By including the key when sending records to a topic, we can ensure that the record is going to be placed into the same partition.
Kafka Consumer Groups
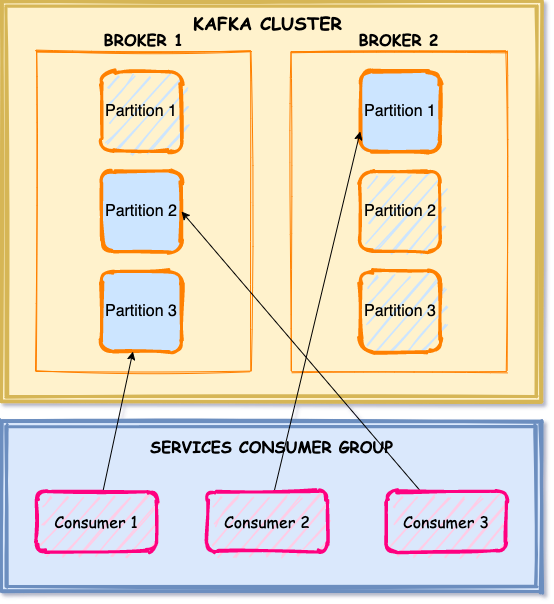
Consumer Groups allow you to consume messages in parallel by assigning partitions to consumers. The maximum amount of parallelism is set by the number of partitions, for example, if a topic has 100 partitions, it can only supports up to 100 active consumers, and if more consumers are available, they are going to be idle waiting for an active consumer to fail, to have its partition assigned.
On the other hand, if a topic has 100 partitions, while a consumer group only has 50 consumers, Kafka will do its best to evenly distribute the partitions across the available consumers, possibly assigning more than one partition per consumer.
NodeJS Microservices with NestJS, Kafka, and Kubernetes – Other Series Posts
- NestJS Kafka and Kubernetes – Part 1
- NodeJS Microservices with NestJS, Kafka, and Kubernetes – Part 2
- NestJS Shared Module Example – Monorepo Setup – Part 3
Conclusion
In this blog post, we looked at how NestJS and Kafka can be used together to build a microservices application that consumes records from a Kafka topic. We also looked at how different DTOs sent to a single topic can be parsed and validated using pipes, class transformers, and validators.
We also considered how partition keys might be used to guarantee that messages are delivered to the same partition, resulting in “First-In, First-Out” (FIFO) ordering. Lastly, we explored how consumer groups may help boost production and consumption throughput by assigning partitions to consumers.
If you liked this post, leave a comment and share with your friends.
All the best,
Thiago Lima
3 replies on “NodeJS Microservices with NestJS, Kafka, and Kubernetes”
[…] NodeJS Microservices with NestJS, Kafka, and Kubernetes – Part 2 […]
[…] NodeJS Microservices with NestJS, Kafka, and Kubernetes – Part 2 […]
[…] NodeJS Microservices with NestJS, Kafka, and Kubernetes – Part 2 […]